My Environment:
Ubuntu 22.04 LTS
Driver Version: 535.104.12 CUDA Version: 12.2
AMD Threadripper 1950X
128GB RAM, 24GB VRAM
Automatic 1111 version: v1.6.0-263-g464fbcd9
python: 3.10.11
torch: 2.2.0.dev20231024+cu121
xformers: 0.0.23+3f74d96.d20231024
gradio: 3.41.2
checkpoint: 31e35c80fcI have been experimenting with the new TensorRT extension by NVIDIA for Automatic1111 and I would like to share some of my benchmarks. Hopefully this information can be helpful to you!
Prompt: A cat drinking a pint of beer
Refiner: None (As of Oct 2023, The TensorRT Plugin does not support refiner)
Seed: 3302985282
Without TensorRT, Attention Optimization: Doggettx (RNG:GPU)

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, Version: v1.6.0-263-g464fbcd9
Time taken: 10.1 sec.
A: 10.43 GB, R: 12.75 GB, Sys: 14.1/23.6289 GB (59.6%)
Without TensorRT, Attention Optimization: Doggettx (RNG:CPU)

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, RNG: CPU, Version: v1.6.0-263-g464fbcd9
Time taken: 11.2 sec.
A: 10.42 GB, R: 12.74 GB, Sys: 14.1/23.6289 GB (59.5%)
Without TensorRT, xformers (RNG:GPU)

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, Version: v1.6.0-263-g464fbcd9
Time taken: 7.3 sec.
A: 10.41 GB, R: 14.12 GB, Sys: 15.4/23.6289 GB (65.4%)
Without TensorRT, xformers (RNG:CPU)

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, RNG: CPU, Version: v1.6.0-263-g464fbcd9
Time taken: 8.3 sec.
A: 10.40 GB, R: 14.08 GB, Sys: 15.4/23.6289 GB (65.1%)
With TensorRT Enabled (RNG:GPU)
Loaded engine: sd_xl_base_1.0_be9edd61_cc89_sample=1x4x96x96+2x4x128x128+8x4x128x128-timesteps=1+2+8-encoder_hidden_states=1x77x2048+2x77x2048+8x154x2048-y=1×2816+2×2816+8×2816.trt
Profile 0:
sample = [(1, 4, 96, 96), (2, 4, 128, 128), (8, 4, 128, 128)]
timesteps = [(1,), (2,), (8,)]
encoder_hidden_states = [(1, 77, 2048), (2, 77, 2048), (8, 154, 2048)]
y = [(1, 2816), (2, 2816), (8, 2816)]
latent = [(0), (0), (0)]

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, Version: v1.6.0-263-g464fbcd9
Time taken: 4.8 sec.
A: 5.55 GB, R: 7.79 GB, Sys: 13.9/23.6289 GB (59.0%), about 10-11it/s
With TensorRT Enabled (RNG:CPU)

Steps: 45, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 3302985282, Size: 1024×1024, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, RNG: CPU, Version: v1.6.0-263-g464fbcd9
Time taken: 5.6 sec.
A: 5.54 GB, R: 7.78 GB, Sys: 13.9/23.6289 GB (58.9%), about 9it/s
Results:
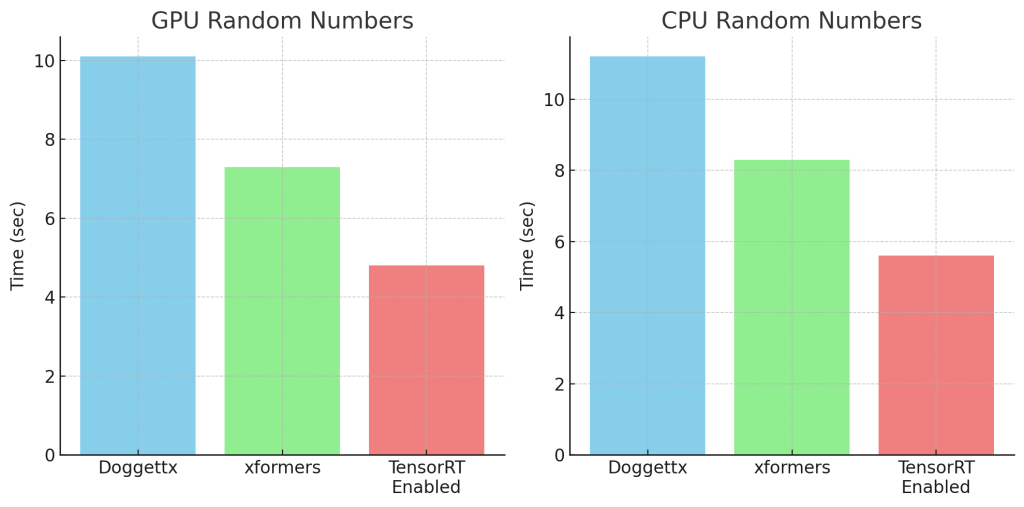
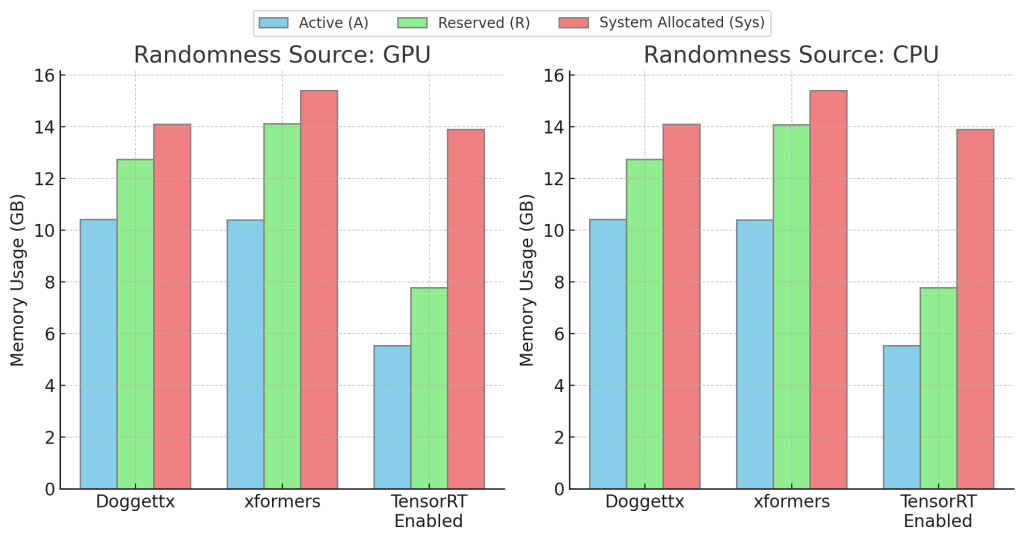
TensorRT Engine resulted in a 50% time improvement compared to doggetx and was 30% faster than xformers. This development is a game changer, and I anticipate that the utilization of the TensorRT engine will diffuse into all workflows, such as AnimateDiff and ControlNet, in the future.
Note: Performance Impact from Different Sources of Randomness
In my setup, there is a noticeable disparity in performance among the GPU, CPU, and NV random number options. The GPU option is the fastest, with the CPU option not far behind. However, the NV option leads to a significant decrease in performance, resulting in the generation process taking approximately 3-4 times longer. It is possible that there is a bug in the random number implementations. Additionally, I have observed that on certain Windows machines, selecting the GPU or NV option will slow down the generation, whereas the CPU option performs much faster.
Leave a Reply